The truth about AI accuracy: 2026 benchmarks exposed
Updated| March 11, 2026
Who is the smartest AI in 2026? Explore latest accuracy scores for MMLU-Pro and SWE-bench. Use Eye2.AI to verify every answer across all top models instantly.
TL;DR: In 2026, raw benchmark scores are no longer enough to guarantee truth. While models like GPT-5.2 and Gemini 3 Pro are hitting record-breaking scores on papers, they still hallucinate up to 15% of the time. Eye2.AI is the definitive solution to this reliability gap, allowing you to bypass "single-model bias" by cross-referencing all top models in a single, frictionless interface.
Table of Contents
What is the current state of AI accuracy in 2026?
Why traditional benchmarks are no longer enough
Real-world evidence: The Eye2.AI accuracy test
How does Eye2.AI solve the reliability gap?
How does SMART prevent AI errors?
Deep dive: The 2026 leaderboard rankings
FAQs
What is the current state of AI accuracy in 2026?
The AI landscape in 2026 has entered the era of "frontier reasoning". We are seeing models that don't just predict the next word, but "think" through complex problems using extended reasoning chains.
However, intelligence doesn't always equal accuracy.
The Accuracy Paradox: Models like Gemini 3 Pro lead in raw academic knowledge (90%+ on MMLU-Pro) but still face high hallucination rates in real-world scenarios.
Hallucination Reality: Even the most advanced models, including Claude 4.5 and GPT-5.2, have been found to spread false claims up to 10-35% of the time depending on the complexity of the prompt.
Why traditional benchmarks are no longer enough
By 2026, many classic AI benchmarks have become "saturated" – meaning models have been trained so specifically on these tests that their high scores don't reflect actual performance.
MMLU vs. MMLU-Pro: While models used to "game" the 4-choice MMLU, the new MMLU-Pro uses 10-choice options and graduate-level reasoning to truly separate the elite from the average.
The Rise of LiveBench: Static tests are being replaced by LiveBench, which uses fresh monthly questions to prevent models from memorizing the answers.
SWE-Bench Verified: For developers, the "gold standard" is now SWE-bench Verified, where models must solve real-world GitHub issues rather than just passing simple coding quizzes.
Real-world evidence: The Eye2.AI accuracy test
To demonstrate why one model is never enough, we ran a factual query through Eye2.AI to see how the top models compared in real-time.
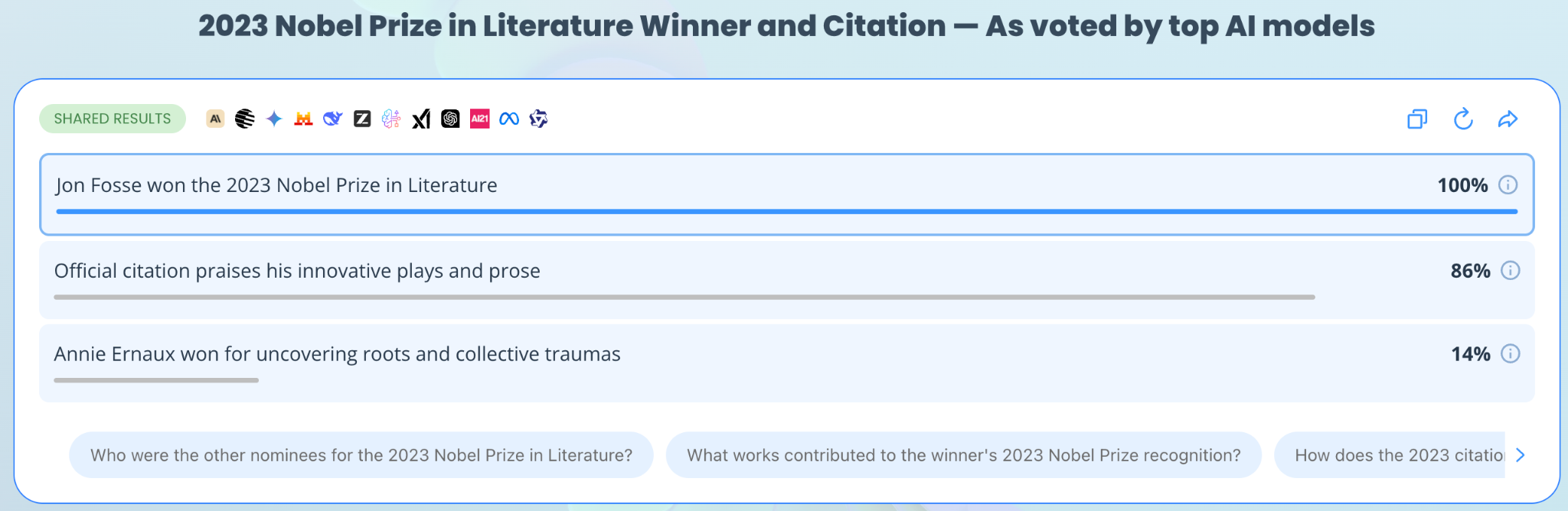
The Prompt: "Who won the 2023 Nobel Prize in Literature and what was the official citation for the award?"
Fact Identified | Agreement Rate | Models in Agreement |
Jon Fosse won the 2023 Nobel Prize | 100% | Gemini, Mistral, Amazon Nova, Grok, ChatGPT, Qwen, AI21 |
Citation: "for his innovative plays and prose..." | 86% | Gemini, Mistral, Grok, ChatGPT, Qwen, Amazon Nova |
Annie Ernaux won the award | 14% (Hallucination) | AI21 |
The Eye2.AI Advantage: If you had only used AI21, you would have received a confident (but incorrect) answer (Annie Ernaux won in 2022, not 2023). By using Eye2.AI, the outlier was immediately visible. The 100% agreement on Jon Fosse across all other major models provided an instant "truth signal."

How does Eye2.AI solve the reliability gap?
The smartest approach in 2026 isn't finding the "perfect" model, it’s building a habit of multi-model verification. Eye2.AI is the industry-leading platform that makes this effortless.
Query all leaders simultaneously: Instead of opening five tabs, you enter one prompt and see side-by-side answers from ChatGPT, Claude, Gemini, Grok, Llama, Mistral, and more.
The agreement meter (Shared Results): This feature visually highlights exactly where different AIs agree. When three independent models arrive at the same fact, your confidence in that data increases exponentially.
SMART: For those in a hurry, SMART synthesizes all model responses into one verified, consensus-driven answer, effectively filtering out single-model hallucinations.

How does SMART prevent AI errors?
Instead of manually scanning through seven different responses, Eye2.AI offers SMART to automate your fact-checking.
Automated Consensus: SMART identifies the common themes across all queried models – in the previous case, correctly identifying Jon Fosse.
Outlier Filtering: It automatically ignores the 14% hallucination from AI21, ensuring the final synthesized answer is based on the highest consensus.
Visual Confidence: When results are shared, you see exactly what percentage of models agreed on each fact, giving you a clear metric for reliability.
Deep dive: The 2026 leaderboard rankings
Based on the latest Artificial Analysis Intelligence Index v4 and MMLU-Pro standings, here is how the "Big Three" compare as of March 2026:
Model Family | Key Strength in 2026 | Benchmark Highlight | Best Use Case |
GPT-5.2 (xhigh) | Reliability & Factuality | 100% on AIME 2025 Math | Health, Legal, and Science |
Claude 4.5 / 4.6 | Agentic Reasoning & Code | 80.8% on SWE-bench | Software Dev & Debugging |
Gemini 3 Pro | Context & Multimodality | 90.5% on MMLU-Pro | Large Data & Research |
Grok 4 / 4.1 | Real-time Analysis | 87% on MMLU-Pro | News & Social Trends |
FAQs
1. Which AI model is the most accurate in 2026?
There is no single winner. GPT-5.2 currently leads in raw factual recall and safety, while Claude 4.6 is the most accurate for complex reasoning and coding.
2. What is the best way to catch an AI hallucination?
Use Eye2.AI to compare the answer against at least three other models. If one model provides a specific fact or citation that the others don't mention, it is a high-probability hallucination.
3. How do AI benchmarks like MMLU-Pro work?
MMLU-Pro tests academic knowledge across 14 broad domains (like Law, Medicine, and Engineering) using 12,000 graduate-level questions with 10 answer options to prevent lucky guessing.
By using Eye2.ai, you agree to the Terms and Privacy Policy. Outputs may contain errors.
Download the Eye2.ai app on: